

KING COUNTY HOUSE PRICES
-
date_range 02/07/2018 14:00 info
In [1]:
##THE LYBRARIES USED IN THIS NOTEBOOK
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn import metrics
import seaborn as sns
from sklearn.ensemble import AdaBoostRegressorWe load the file into pandas to see which features the dataset has
This dataset contains house sale prices for King County, which includes Seattle. It includes homes sold between May 2014 and May 2015. Here you have the Kaggle competition . I start with this dataset as I followed the ones in the course from Washington University in Coursera. If you want to take a look to the contents from the course Machine Learning Foundations
Here you can find a brief version of the features in the dataset:
- Price
- Bedrooms
- Bathrooms
- Sqft living
- Sqft_lot
- Floors
and so on
In [2]:
dataset_link = 'https://bit.ly/2GxNbuV'
houses_df = pd.read_csv(dataset_link)
minimum_y = houses_df['price'].min()
# s refers to size
#alpha --> 0.0 transparent through 1.0 opaque
plt.scatter(x = houses_df.sqft_living,y = houses_df.price/minimum_y,s = 1, alpha = 1)
plt.xlabel("SQFT_LIVING")
plt.ylabel("PRICES")
plt.title("SEATTLE HOME PRICES")
plt.yscale('log')
#Lets see what we have in the dataset
houses_df.head()| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| ID | 7129300520 | 6414100192 | 5631500400 | 2487200875 | 1954400510 |
| DATE | 20141013T000000 | 20141209T000000 | 20150225T000000 | 20141209T000000 | 20150218T000000 |
| PRICE | 221900 | 538000 | 180000 | 604000 | 510000 |
| BEDROOMS | 3 | 3 | 2 | 4 | 3 |
| BATHROOMS | 1.0 | 2.25 | 1.00 | 3.00 | 2.00 |
| SQFT_LIVING | 1180 | 2570 | 770 | 1960 | 1680 |
| SQFT_LOT | 5650 | 7242 | 10000 | 5000 | 8080 |
| FLOORS | 1.0 | 2.0 | 1.0 | 1.0 | 1.0 |
| WATERFRONT | 0 | 0 | 0 | 0 | 0 |
| VIEW | 0 | 0 | 0 | 0 | 0 |
| GRADE | 7 | 7 | 6 | 7 | 8 |
| SQFT_ABOVE | 1180 | 2170 | 770 | 1050 | 1680 |
| SQFT_BASEMENT | 0 | 400 | 0 | 910 | 0 |
| YEAR_BUILT | 1955 | 1951 | 1933 | 1965 | 1987 |
| YEAR_RENOVATED | 0 | 1991 | 0 | 0 | 0 |
| ZIPCODE | 98178 | 98125 | 98028 | 98136 | 98074 |
| LAT | 47.5112 | 47.7210 | 47.7379 | 47.5208 | 47.6168 |
| LONG | -122.257 | -122.319 | -122.233 | -122.393 | -122.045 |
| SQFT_LIVING15 | -1340 | -1690 | -2720 | -1360 | -1800 |
| SQFT_LOT15 | -5650 | -7639 | -8062 | -5000 | -7503 |
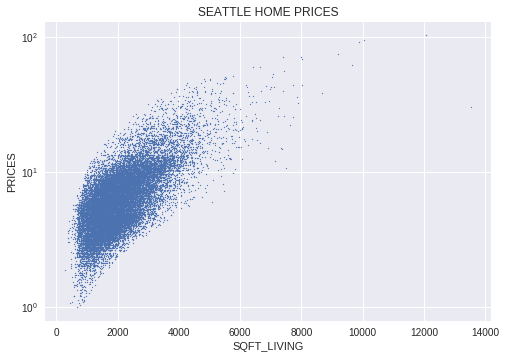
We use a log scale as it allows a large range of elements to be displayed without small values being compressed down into bottom of the graph. If you want to see how you appreciate the change between a normal and log scale, check out this question in Stackoverflow
Explore the data
In [3]:
pd.set_option('display.float_format', lambda x: '%.3f' % x) #supress scientific notation
houses_df.describe().iloc[:,1:].drop(['yr_built','yr_renovated','zipcode'],axis=1)| COUNT | MEAN | STD | MIN | 25% | 75% | MAX | |
|---|---|---|---|---|---|---|---|
| Price | 21613 | 540088 | 367127 | 75000 | 321950 | 645000 | 7700000 |
| Bedrooms | 21613 | 3371 | 0.930 | 0.000 | 3.000 | 4.000 | 33.000 |
| Bathrooms | 21613 | 2.115 | 0.770 | 0.000 | 1750 | 2500 | 8000 |
| Sqft_Living | 21613 | 2079 | 918 | 290 | 1427 | 2550 | 13540 |
| Sqft_Lot | 21613 | 15106 | 41420 | 520 | 5040 | 10688 | 1651359 |
| Floors | 21613 | 1.494 | 0.540 | 1.000 | 1.000 | 2.000 | 3500 |
| Sqft_above | 21613 | 1788 | 828 | 290 | 1190 | 2210 | 9410 |
| Sqft_Basement | 21613 | 291.509 | 442.575 | 0 | 0 | 560 | 4820 |
The average sale price of a house in our dataset is close to $540,088 with most of the values falling within $321,950 to $645,000 range.
Pearson Correlation
To see how each variable is correlated to the other we are gonna use the Pearson Correlation Coeficient. This is a measure of the linear correlation between two variables X and Y. It has a value between +1 and −1, where 1 is total positive linear correlation, 0 is no linear correlation, and −1 is total negative linear correlation.
For any more information refer to Pearson Correlation Coefficient
In [4]:
correlation = houses_df.iloc[:,2:].corr(method='pearson')
correlation.style.format("{:.2}").background_gradient(cmap=plt.get_cmap('coolwarm'), axis=1)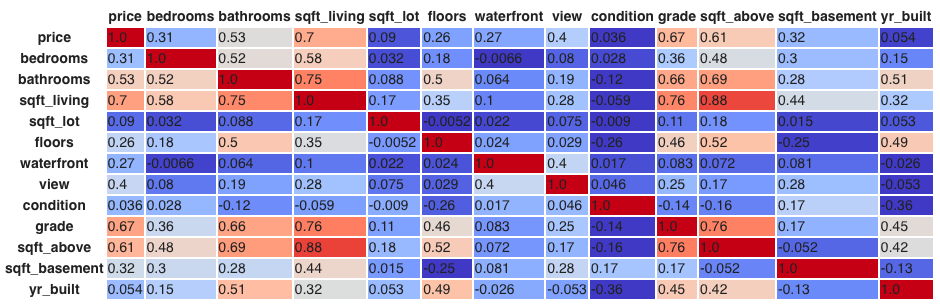
In [5]:
correlation.price.sort_values(ascending=False)[1:]
#we drop the first value as it is with itself.| VARIABLES | VALUES |
|---|---|
| Sqft_Living | 0.702 |
| Grade | 0.667 |
| Sqft_above | 0.606 |
| Sqft_Living15 | 0.585 |
| Bathrooms | 0.525 |
| View | 0.397 |
| Sqft_Basement | 0.324 |
| Bedrooms | 0.308 |
| Lat | 0.307 |
| Waterfront | 0.266 |
| Floors | 0.257 |
| Yr_renovated | 0.126 |
| Sqft_lot | 0.090 |
| Sqft_lot15 | 0.082 |
| Yr_built | 0.054 |
| Condition | 0.036 |
| Long | 0.022 |
| Zipcode | -0.053 |
All the features are positively correlated with the House Price, except zipcode. The correlation of Price with Sqft_Living is the greatest with 0.702. A negative correlation between two variables means that one variable increases whenever the other decreases. We can see the biggest minimum of every column right below.
In [6]:
correlated_variables = correlation.idxmin()
correlation_values = correlation.min().values
correlation_dict = {'First Variable':correlated_variables.index, 'Second Variable':correlated_variables.values, 'Values':correlation_values}
pd.DataFrame(correlation_dict)| FIRST VARIABLE | SECOND VARIABLE | VALUES | |
|---|---|---|---|
| 0 | price | zipcode | -0.053 |
| 1 | bedrooms | zipcode | -0.153 |
| 2 | bathrooms | zipcode | -0.204 |
| 3 | sqft_living | zipcode | -0.199 |
| 4 | sqft_lot | zipcode | -0.130 |
| 5 | floors | condition | -0.264 |
| 6 | waterfront | long | -0.042 |
| 7 | view | long | -0.078 |
| 8 | condition | yr_built | -0.361 |
| 9 | grade | zipcode | -0.185 |
| 10 | sqft_above | zipcode | -0.261 |
| 11 | sqft_basement | floors | -0.246 |
| 12 | yr_built | condition | -0.361 |
| 13 | yr_renovated | yr_built | -0.225 |
| 14 | zipcode | long | -0.564 |
| 15 | lat | yr_built | -0.148 |
| 16 | long | zipcode | -0.564 |
| 17 | sqft_living15 | zipcode | -0.279 |
| 18 | sqft_lot15 | zipcode | -0.147 |
Data Visualization
Now we are gonna pick the most interesting columns in this case, price,sqft_living,sqft_lot bedrooms, bathrooms and yr_built,to see how each other is correlated to one another.
In [7]:
sns.set(style = "ticks", color_codes=True)
correlation_features = ['price','bedrooms','bathrooms','sqft_living','sqft_lot','yr_built']
sns.set_style("darkgrid")
sns.pairplot(houses_df[correlation_features], size = 2.75,diag_kind="kde",dropna=True)
#diag_kind:Use kernel density estimates for univariate plots:
#kind:Fit linear regression models to the scatter plots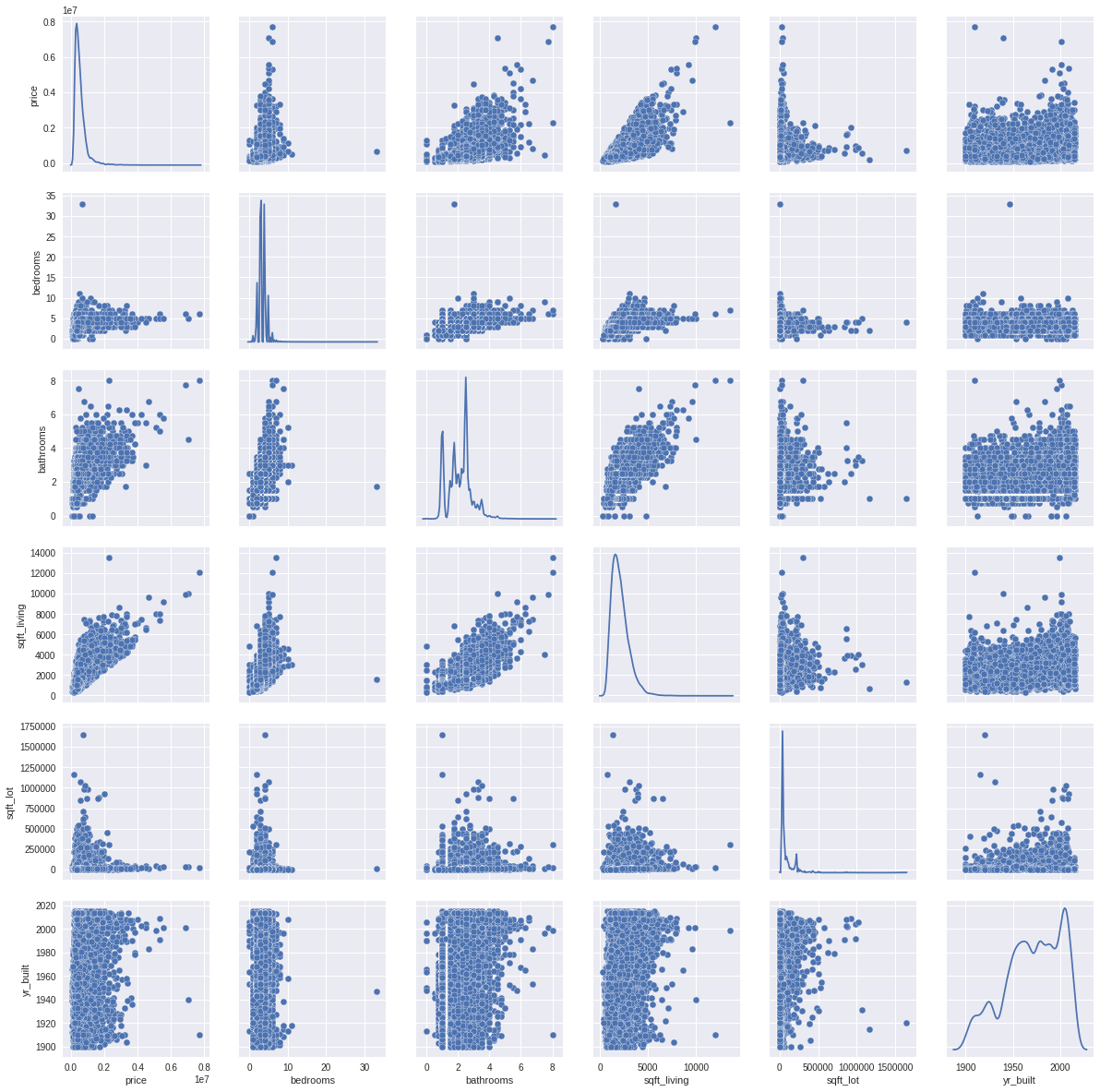
By looking to the scatter plots you can observe the next :
Here you can find the intervals to classify the correlation I think the most difficult plot to analyze is the one from Year Built because they almost all look the same. Thats when it is useful if we calculate the Pearson coefficient along the plots.
Lets divide the dataset into training and test
In [8]:
dataset_train, dataset_test, price_train, price_test = train_test_split(houses_df,houses_df['price'],test_size=0.2,random_state=3)Building a Linear Regressor
Regression is the process of estimating the relationship between input data and the continuous-valued output data. This data is usually in the form of real numbers, and our goal is to estimate the underlying function that governs the mapping from the input to the output.
Ordinary Least Squares
The first method we use is ordinary least squares and the idea behind is to find the best line that fits the data.
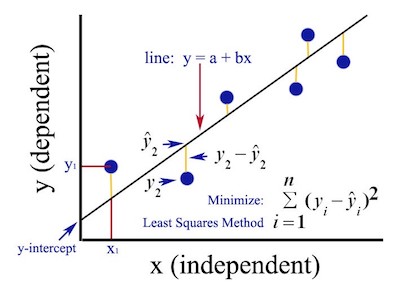
The error function or also called the loss function \(\epsilon_i\) is the difference between the observed values of y y i and the predicted values of y ŷi . This term is called Residual sum of squares for more information RSS
The linear model is written as:
\[y_i = a + bx_i + \epsilon_i\]The ordinary least squares (OLS) seeks the coefficient \(a\) and \(b\). The goal is to find values of 𝑎 and 𝑏 that minimize the error. We redefine the error by the next formula
\[\epsilon(a,b)=\sum_{i=1}^n (y_i−ŷ )^2= \sum_{i=1}^n(y_i−(a+bx_i))^2\]This requires us to find the values of (𝑎, 𝑏) such that the gradient of \(\epsilon\) with respect to our variables (which are 𝑎 and 𝑏) vanishes; then we require:
\[\frac {∂\epsilon}{∂a}=0\] \[\frac {∂\epsilon}{∂b}=0\]Differentiating \(\epsilon(𝑎, 𝑏)\) yields:
\[\frac {∂\epsilon}{∂a}= 2\sum_{i=1}^n (y_i-a-bx_i)(-1)\] \[\frac {∂\epsilon}{∂b}= 2\sum_{i=1}^n (y_i-a-bx_i)(-x_i)\]To solve this equations remember to use:
\[\bar{X} =\sum_{i=1}^n \frac{1}{n} x_i\]So we will end up with the following coefficients:
\[a=\bar{y}−b\bar{x}\] \[b=\frac {\sum_{i=1}^n (x_i−\bar{x})(y_i−\bar{y})}{\sum_{i=1}^n(x_i−\bar{x})^2}\]RMSE –> Root Mean Square Error
It indicates how close the observed data points are to the model's predicted values. Lower values of RMSE indicate better fit. RMSE is a good measure of how accurately the model predicts the response, and is the most important criterion for fit if the main purpose of the model is prediction.
The main advantages of using Least Squares are:
- Applicability: There are hardly any applications where least squares doesn’t work
- Calculations are very fast
- Has no paramaters to tune
Disadvantages:
- Sensitivity to outliers
- Tendency to overfit data. If we have many features the learned hypothesis may fit the training set very well but fail to generalize to new examples
Let's train the model only taking into account one feature from the dataset, in this case we pick up Square feet living
In [9]:
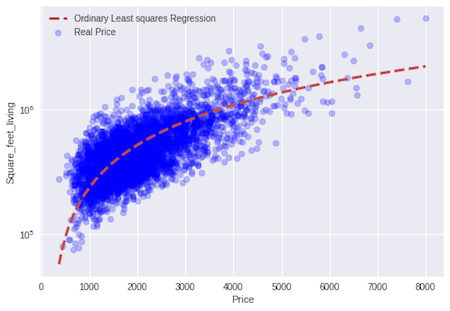
#Build the regression model using only sqft_living as a feature
# Create linear regression object
regression_ols = linear_model.LinearRegression()
#We convert the column sqft_living to a numpy array to make it easier to work
living_train = np.asarray(dataset_train.sqft_living)
living_train = living_train.reshape(-1,1)
#Train the model using the training sets
#Here price is the "target" data in this model, the other features are the independet variables
ols_model = regression_ols.fit(living_train, price_train)
living_test = np.asarray(dataset_test.sqft_living)
living_test = living_test.reshape(-1,1)
#We the trained dataset we make a prediction for the test dataset
prediction_test_ols = ols_model.predict(living_test)
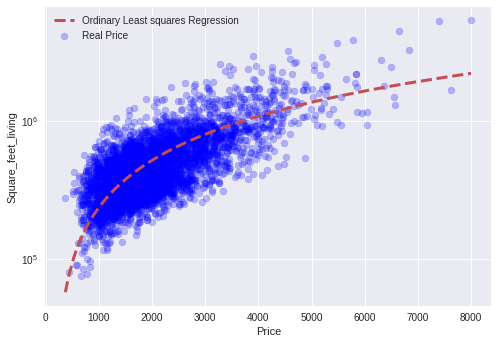
print ('Ordinary Least Squares')
#Coefficient
print('Coefficient:',ols_model.coef_[0])
print ('Intercept', ols_model.intercept_)
# Apply the model we created using the training data to the test data, and calculate the RSS.
print('RSS',((price_test - prediction_test_ols) **2).sum())
# Calculate the RMSE ( Root Mean Squared Error)
print('RMSE', np.sqrt(metrics.mean_squared_error(price_test,prediction_test_ols)))
#The model's performance on test set is:
print('The model\'s performance is %.2f\n'% ols_model.score(living_test, price_test))
living_test_sort = np.sort(living_test.reshape(-1))
plt.scatter(living_test, price_test, color='blue', alpha=0.25,label='Real Price')
#When you plot you have to sort the array, in this case square feet living , the one that belongs to the test, if you dont do this, the plot looks weird
plt.plot(living_test_sort, ols_model.predict(living_test_sort.reshape(-1,1)),'r--',linewidth=3, label='Ordinary Least squares Regression')
plt.xlabel('Price')
plt.ylabel('Square_feet_living')
plt.legend()
plt.yscale('log')
#Blue dots are from the original data the red line is the prediction from the least squares
plt.show()
Ordinary Least Squares
Coefficient: 282.24681417145496
Intercept -47235.80881852331
RSS 279538022220474.28
RMSE 254289.1477693324
The model's performance is: 0.50
In [10]:
actual_predicted_data_ols = pd.DataFrame({'Actual': price_test, 'Predicted': np.round(prediction_test_ols,decimals=3)})
actual_predicted_data_ols.head()| Actual | Predicted | |
|---|---|---|
| 4131 | 525000 | 404359.094 |
| 17459 | 1870000 | 1225697.323 |
| 2192 | 750000 | 853131.528 |
| 12418 | 244900 | 127757.216 |
| 15773 | 275000 | 356377.135 |
Lasso Regression
It's a shrinkage and variable selection method. LASSO is an acronym form Least Absolute selection and Shrinkage Operator. The Lasso imposes a constraint on the sum of the absolute values of the model parameters where the sum has a specified constant as an upper bound. This constraint causes regression coefficients for some variables to shrink towards zero. The shrinkage process identifies the variables most strongly associated with the response variable. The goal is to obtain the subset of predictors that minimized the prediction error. You should use this method when you hove more than two features at least.
\[Y= \beta_1X_1 + \beta_2X_2 + \beta_3X_3 + b\]\(\beta_1 , \beta_2 , \beta_3\) are coefficients of regression
\(X_1, X_2, X_3\) are features
The Lasso method uses \(L_1\) regularization. What is that? It’s a way of avoiding overfitting.
\[\|X\|_1 = \sum_{i=1}^n|x_i|\]\(L_1\) norm is the sum of the absolute value of the coefficients.
The cost function in Lasso is the next formula:
\[\epsilon = Error + Penalty\] \[\epsilon(a,b)=\sum_{i=1}^n (y_i−ŷ )^2 + \lambda\sum_{j=1}^p |\beta_j|\] \[\epsilon(a,b)=\sum_{i=1}^n(y_i−(\sum_{j=1}^p x_{ij}\beta_j))^2 +\lambda\sum_{j=1}^p|\beta_j|\]Tuning paramater λ :
It is to control the strenght of the penalty.
- \(\lambda\) increases more coefficients are reduced to zero
- \(\lambda\) is zero then it’s OLS Regression.
- \(\lambda \rightarrow \infty\) : we get \(\beta=0\) all coefficients are eliminated
- \(\lambda\) increases, bias increases.
- \(\lambda\) decreases, variance increases
The bias is an error from erroneous assumptions in the learning algorithm. High bias can cause an algorithm to miss the relevant relations between features and target outputs(underfitting).The variance is an error from sensitivity to small fluctuations in the training set. High variance can cause an algorithm to model the random noise in the training data, rather than the intended outputs (overfitting). For more information learn about the Bias and VarianceTradeoff
Advantages
- Greater prediction accuracy
- Increase model interpretability. Reduce variance without a substantial increase in bias.
- The regression coefficients for unimportant variables are reduced to zero and produces a simple model that selects only the most important predictors.
Disadvantages
- If coefficients are correlated , Lasso arbitrarily chooses only one of them.
- Estimating p-values is not very straightforward
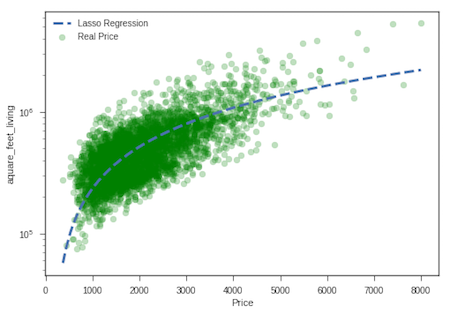
In [11]:
regression_lasso = linear_model.Lasso(alpha=.1)
lasso_model = regression_lasso.fit(living_train, price_train)
prediction_test_lasso = lasso_model.predict(living_test)
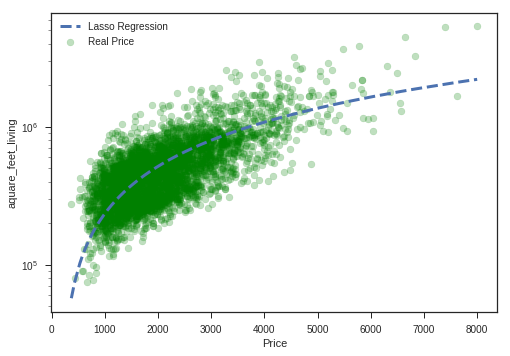
print ('Lasso Regression')
#Intercept
print ('Intercept', lasso_model.intercept_)
# Coefficient
print('Coefficient:', lasso_model.coef_[0])
# Apply the model we created using the training data to the test data, and calculate the RSS.
print('RSS',((price_test - prediction_test_lasso) **2).sum())
# Calculate the RMSE (Root Mean Squared Error)
print('RMSE', np.sqrt(metrics.mean_squared_error(price_test,prediction_test_lasso)))
# Coefficient of determination R^2 of the prediction
print('The model\'s performance is %.2f\n' % lasso_model.score(living_test, price_test))
# Plot
plt.scatter(living_test, price_test, color='green', alpha=0.25,label='Real Price')
plt.plot(living_test_sort, lasso_model.predict(living_test_sort.reshape(-1,1)),'b--',linewidth=3, label='Lasso Regression')
plt.xlabel('Price')
plt.ylabel('aquare_feet_living')
plt.legend()
plt.yscale('log')
plt.show() Lasso Regression
Intercept -47235.808571451926
Coefficient: 282.24681405273867
RSS 279538022213446.22
RMSE 254289.14776613575
The model's performance is : 0.50
In [12]:
actual_predicted_data_lasso = pd.DataFrame({'Actual': price_test, 'Predicted': np.round(prediction_test_lasso,decimals=3)})
actual_predicted_data_lasso.head()| Actual | Predicted | |
|---|---|---|
| 4131 | 525000 | 404359.094 |
| 17459 | 1870000 | 1225697.323 |
| 2192 | 750000 | 853131.528 |
| 12418 | 244900 | 127757.216 |
| 15773 | 275000 | 356377.136 |
Ridge Regression
Aims to avoid overfitting adding a cost to the RSS term of OLS. A tuning parameter \(\lambda\) controls the strength of the penalty.The \(\lambda\) parameter is a scalar that should be learned using cross validation. The penalty uses the \(L_2\) (euclidean length) of the coefficient vector .
The Ridge method uses \(L_2\) regularization. What is that? It’s a way of avoiding overfitting.
\[\|X\|_2 =\sum_{i=1}^n|x_i|^2\]\(L_2\) norm is the sum of the squared value of the coefficients.
The cost function in Ridge is the next formula:
\[\epsilon = Error + Penalty\] \[\epsilon(a,b)=\sum_{i=1}^n (y_i−ŷ )^2 + \lambda\sum_{j=1}^p |\beta_j|^2\] \[\epsilon(a,b)=\sum_{i=1}^n(y_i−( \sum_{j=1}^p x_{ij}\beta_j))^2 +\lambda\sum_{j=1}^p|\beta_j| ^2\]Tuning parameter λ :
- When \(\lambda = 0\), we get the linear regression estimate
- When \(\lambda\rightarrow \infty\),we get \(\beta_{j} =0\)
- For \(\lambda\) in between, we are balancing two ideas: fitting a linear model of y on X, and shrinking the coefficients
As Lasso regression \(\rightarrow\) The bias increases as \(\lambda\) (amount of shrinkage) increases. And the variance decreases as \(\lambda\) increases The amount of shrinkage is controlled by \(\lambda\), the tuning parameter that multiplies the ridge penalty. Large λ means more shrinkage, and so we get different coefficient estimates for different values of λ. Choosing an appropriate value of λ is important, and also difficult.
Advantages
- Ridge regression performs particularly well when there is a subset of true coefficients that are small or even zero.
- Sparsity (Doesn’t produce sparse results i.e. it does not shrink coefficients all the way to zero)
Disadvantages
- It doesn’t do as well when all of the true coefficients are moderately large
In [13]:
regression_ridge = linear_model.Ridge(alpha=[.1])
ridge_model = regression_ridge.fit(living_train, price_train)
prediction_test_ridge = ridge_model.predict(living_test)
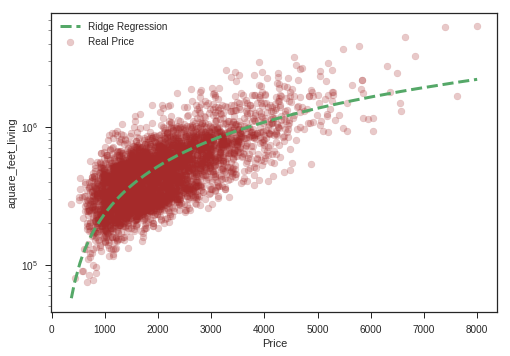
print ('Ridge Regression')
#Intercept
print ('Intercept', ridge_model.intercept_)
# Coeficient
print('Coefficient:', ridge_model.coef_[0])
# Apply the model we created using the training data to the test data, and calculate the RSS.
print('RSS',((price_test - prediction_test_ridge) **2).sum())
# Calculate the RMSE (Root Mean Squared Error)
print('RMSE', np.sqrt(metrics.mean_squared_error(price_test,prediction_test_ridge)))
# Coefficient of determination R^2 of the prediction
print('The model\'s performance is %.2f\n' % ridge_model.score(living_test, price_test))
# Plot
plt.scatter(living_test, price_test, color='brown', alpha=0.25,label='Real Price')
plt.plot(living_test_sort, ridge_model.predict(living_test_sort.reshape(-1,1)),'g--',linewidth=3, label='Ridge Regression')
plt.xlabel('Price')
plt.ylabel('aquare_feet_living')
plt.legend()
plt.yscale('log')
plt.show()
Ridge Regression
Intercept -47235.808814489865
Coefficient: 282.2468141695169
RSS 279538022220359.56
RMSE 254289.14776928021
The model's performance is: 0.50
In [14]:
actual_predicted_data_ridge = pd.DataFrame({'Actual': price_test, 'Predicted': np.round(prediction_test_ridge,decimals=3)})
actual_predicted_data_ridge.head()| Actual | Predicted | |
|---|---|---|
| 4131 | 525000 | 404359.094 |
| 17459 | 1870000 | 1225697.323 |
| 2192 | 750000 | 853131.528 |
| 12418 | 244900 | 127757.216 |
| 15773 | 275000 | 356377.135 |
AdaBoost Algorithm
AdaBoost stands for Adaptive Boosting. When we mention boosting we refer to aggregate a set of weak classifiers into a strong classifier. It is adaptive in the sense that classifiers that come in next for execution are adjusted according to those instances that were wrongly classified width the previous classifiers. You could say that by just focusing on the training data samples misclassified by the previous weak classifier, each weak classifier contributes its bit the best it can to improve the overall classification rate. AdaBoost calls the weak classifiers repeatedly, performing a series of \(t = 1,...,T\) classifiers. In each execution, “weight” calculated by incorrectly classified examples increases (or, alternatively, weights of each correctly classified examples decreases). New classifiers are constrained to focus on those examples that were incorrectly classified by previous classifiers.
Disadvantages
- It is sensitive to noisy data and information that doesn’t belong to the required set
Advantages
- In some situations, this algorithm may be less susceptible to memory input set in comparison to many other algorithms
Basic Idea
1- Take lots of (possibly) weak predictors
2- Weight them and add them up
3- Get a stronger predictor
First : Initialize the weight of each observation to \(W_i =\frac { 1}{N}\) For \(t\) in 1 to T do the following.
Second : Using the weights, learn model \(h_t(x_i) : X \rightarrow [0,1]\)
Third : Compute
\(\epsilon =\sum_{i=1}^{n} w_i^t | y_i −h_t (x_i )|\)
as the error for \(h_t\)
Fourth : Let \(\beta_{t}\) = \(\frac {\epsilon_{t}}{1 - \epsilon_{t}}\) and update the weights of each of the observations as \(w_i ^{(t+1)} = w_i^{(t)}\beta_{t}^{1-|y_i -h_t(x_i)|}\) This scheme increases the weights of observations poorly predicted by \(h_t\)
Fifth : Normalize \(w^{t+1}\) so that they sum to one
In [15]:
#n_estimators: It controls the number of weak learners.
#learning_rate:Controls the contribution of weak learners in the final combination. There is a trade-off between learning_rate and n_estimators.
#base_estimators: It helps to specify different ML algorithm. By default sklearn uses decision tree
adaboost_regressor = AdaBoostRegressor(n_estimators=1500, learning_rate = 0.001, loss='exponential')
ada_model = adaboost_regressor.fit(living_train, price_train)
prediction_test_ada = ada_model.predict(living_test)
# Apply the model we created using the training data to the test data, and calculate the RSS.
print('RSS',((price_test - prediction_test_ada) **2).sum())
# Calculate the RMSE (Root Mean Squared Error)
print('RMSE', np.sqrt(metrics.mean_squared_error(price_test,prediction_test_ada)))
#Coefficient of determination R^2 of the prediction
print('The model\'s performance is %.2f\n' % ada_model.score(living_test, price_test))
# Plot
plt.scatter(living_test, price_test, color='black', alpha=0.25,label='Real Price')
plt.plot(living_test_sort, ada_model.predict(living_test_sort.reshape(-1,1)),'g--',linewidth=3, label='AdaBoost regressor')
plt.xlabel('Price')
plt.ylabel('aquare_feet_living')
plt.legend()
plt.yscale('log')
plt.show()
RSS 262076146288792.1
RMSE 246218.7540170321
The model's performance is: 0.53
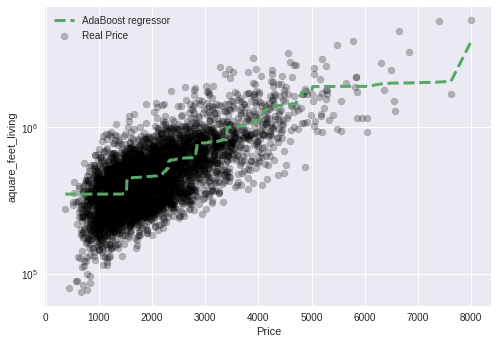
In [16]:
actual_predicted_data_ada = pd.DataFrame({'Actual': price_test, 'Predicted': np.round(prediction_test_ada,decimals=3)})
actual_predicted_data_ada.head()| Actual | Predicted | |
|---|---|---|
| 4131 | 525000 | 442630.127 |
| 17459 | 1870000 | 1469039.993 |
| 2192 | 750000 | 777804.825 |
| 12418 | 244900 | 343675.471 |
| 15773 | 275000 | 347800.098 |
Let's train the model adding more features
If we have too many features and we are not sure which ones might work the best, you can carry out a feature selection step through either PCA (Principal Components Analysis) or LDA (Linear Discriminant Analysis)
Polynomial Curve Fitting
Consider the general form for a polynomial of order N
\[\hat y(x) = a_0 + a_1x^1 + a_2x^2 + ...... a_nx^n = a_0 +\sum_{i=1}^n a_ix^i\]Just as was the case for linear regression, we ask, how can we pick the coefficients that best fits the curve to the data? We use the same idea: The curve that gives minimum error between data and the fit \(\hat y (x )\) is ‘the best’
Error - Least squares approach
As we mentioned before the error using the least squares approach is: \(\epsilon(x)= \sum_{i=1}^n (y_i - \hat y)^2\)
\[\epsilon(x)= \sum_{i=1}^n (y_i - (a_0 + a_1x_i^1 +a_2x_i^2 + a_3x_i^3... ))^2\]where ‘i’ is the current point and ‘n’ is the total number of points that we have
\[\epsilon(x)=\sum_{i=1}^n (y_i - (a_0 +\sum_{j=1}^k a_jx^j ))^2\]To minimize this equation we proceed to take the derivative respect to each coefficient in order to find the best curve
In [17]:
dataset_train, dataset_test = train_test_split(houses_df,test_size=0.2,random_state=3)
price_train= np.asarray(dataset_train.price).reshape(-1,1)
my_features = ['bedrooms', 'bathrooms', 'sqft_living', 'sqft_lot', 'floors','yr_built','zipcode']
train_matrix = dataset_train.as_matrix(my_features)
regr_with_more_features = linear_model.LinearRegression()
model_least_squares = regr_with_more_features.fit(train_matrix, price_train)
matrix_test = dataset_test.as_matrix(my_features)
price_test_multiple_regression = np.asarray(dataset_test.price).reshape(-1,1)
prediction_test_least_squares = model_least_squares.predict(matrix_test)
print ('Least Squares Means')
#Coefficient
print('Coefficient:',model_least_squares.coef_[0])
#Apply the model we created using the training data to the test data, and calculate the RSE.
print('RSS',((price_test_multiple_regression - prediction_test_least_squares) **2).sum())
# Calculate the MSE
print('RMSE', np.sqrt(metrics.mean_squared_error(price_test_multiple_regression,prediction_test_least_squares)))
# Coefficient of determination R^2 of the prediction
print('The model\'s performance is %.2f\n' % model_least_squares.score(matrix_test, price_test_multiple_regression))
Least Squares Means
Coefficient: [-6.66351683e+04 6.66137331e+04 3.04489220e+02 -2.82811904e-01
5.38124224e+04 -3.39351106e+03 6.28399203e+01]
RSS 248170780815915.44
RMSE 239597.73367059807
The model's performance is: 0.55
In [18]:
actual_predicted_data_least_squares = pd.DataFrame({'Actual': price_test_multiple_regression, 'Predicted': np.round(prediction_test_least_squares,decimals=3)})
actual_predicted_data_least_squares.head()| Actual | Predicted | |
|---|---|---|
| 4131 | 525000 | 348437.108 |
| 17459 | 1870000 | 1328478.319 |
| 2192 | 750000 | 791693.408 |
| 12418 | 244900 | 264810.433 |
| 15773 | 275000 | 347495.643 |
Putting all together
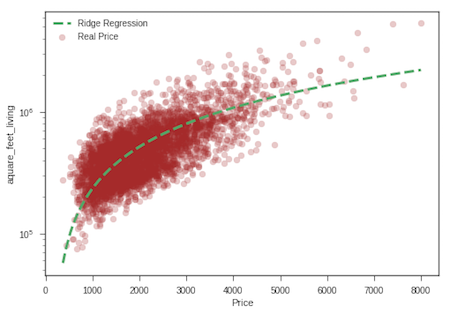
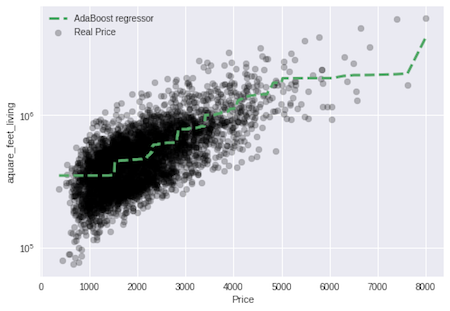
So this is the part that you ask yourself: How do I choose the best model that represents my data? In this particularly case we have to look at:
-\(RMSE\)
-\(R^2\)
I will detail a little bit about the last one. \(R^2\) It’s the coefficient of determination. It explains how good is your model when compared to the baseline model. The math formula is given by:
\[R^2 = 1 - \frac{SS_{res}}{SS_{tot}}\]Where:
-
\(\bar{y}\) is the mean of the observed data:
-
\(y_i\) represents the observed values
\[SS_{tot} =\sum_{i=1}^n (y_i - \bar{y})^2\]\(SS_{tot}\) quantifies how much the data points \(y_i\) varies from their mean \(\bar{y}\)
\[SS_{res} = \sum_{i=1}^n (y_i - \hat{y})^2\]\(SSE_{res}\) quantifies how much the data points, \(y_i\) varies around the estimated regression \(\hat{y}\)
If this number is large, it is said, the regression gives a good fit . When is a large number? Well R goes from 0 to 1 for linear regressions.
- \(R^2\) = 1 indicates that the regression predictions perfectly fit the data.
- \(R^2\) = 0 indicates that the estimated regression line is perfectly horizontal
So… How do we interpret this coefficient?
”\(R^2\) ×100 percent of the variation in y is accounted for by the variation in predictor x.”
If \(R^2\)=0.55 then it means 55% variations in House prices is accounted for by the variation in Square Feet Living..
If you want to read more about this, check the Statistics Program from Pennsylvania State University
As for RMSE, the lowest the better, because it means that our prediction line is not varying that much from the actual values So taking all this into account. Which are ours best models? According to \(R^2\) and \(RMSE\), our best pick is Linear regression with more features and then Adaboost algorithm. As for Linear regression if we take under consideration all the features probably we are going to have a better model. Thats all for today, folks. I hope this comes useful to someone and don’t hesitate if you have any doubt, or see an error. Drop a line!